How to Create an Automated Profile README using Nodejs and GitHub Actions

undefined or mostly null.
Some years ago, GitHub introduced the new Profile README feature that allowed GitHub users to pin a markdown file on their profile using a special repository named after their GitHub username. Since then, developers have used this file as a quick portfolio and for highlighting their achievements. I wrote an article shortly after the release to share how to set it up and highlight some cool profiles I had seen. This tutorial is a sequel to that article, and I will share how I took my GitHub profile to the next level with the power of scripting and CI/CD automation.
In this article, you'll learn how to automate your GitHub README Profile so that it can update itself anytime you want. We will make this possible using a custom script built with Nodejs/TypeScript, markdown-it library, GitHub API, RSS feeds, and GitHub Actions. If you want to see the code, you can head to this repository, but you should read along to learn one or two things you can apply in other use cases (especially if you're new to writing automated scripts).
Prerequisites
To get the best out of this tutorial, you need to know/do the following:
Have an existing GitHub account.
Read the first article and create your README profile.
Have Nodejs and NPM installed on your computer.
Some prior knowledge of the JavaScript programming language.
The Problem
GitHub allows you to pin only six (6) repositories on your profile. I wanted to highlight more repositories while retaining the existing ones in the most minimal way possible (without having to use these kinds of badges). I also wanted a way to highlight some content from my newsletter so I can get some traffic from there and potentially new subscribers that fit my target audience. I remember seeing some profiles in the past that listed their latest blog posts or music they were listening to. So I researched, found some of those profiles, and discovered they ran a script that automatically generated their markdown file. I then decided to make mine.
The Proposed Solution
Generally, the README file is written in markdown, a markup language for creating formatted text. The goal is to simultaneously generate the entire markdown file, including the static and dynamic sections. This includes the badges, open-source statistics, and text descriptions. The new dynamic sections are the following:
List of selected GitHub repositories.
List of my recent blog posts.
List of my recent newsletters.
Getting Started
We can easily use markdown-it, a markdown parser for rendering a mix of JavaScript and plain text into a markdown file. To get started, kindly create a new directory with the following file structure:
┌── .github
┌── workflows
├── build.yml
┌── src
├── app.ts
├── fetchGitHubData.ts
├── fetchRssData.ts
├── package.json
└── tsconfig.json
Next, install the required packages using the command below:
npm install fs markdown-it rss-parser tsc-watch
npm install --save-dev @types/node
I'm using TypeScript and will use ts to compile to JavaScript during the build. My tsconfig.json and package.json scripts file looks looks like this:
// tsconfig.json
{
"compilerOptions": {
"target": "ES2015",
"module": "commonjs",
"strict": true,
"moduleResolution": "node",
"esModuleInterop": true,
"skipLibCheck": true,
"forceConsistentCasingInFileNames": true,
"outDir": "build"
},
"include": ["src/*"]
}
// package.json
{
"name": "bolajiayodeji",
"version": "1.0.0",
"description": "Bolaji Ayodeji's GitHub Profile",
"main": "src/app.ts",
"scripts": {
"build": "npx tsc",
"build:watch": "npx tsc-watch",
"start": "npm run build && node build/app.js",
"test": "echo \"Error: no test specified\" && exit 1"
},
...
}
Fetching the Data from GitHub API
You can fetch different kinds of data with GitHub's API. There are two options: use the API directly or the Octokit.js library (this is the route GitHub recommends). I decided to use the API directly since the Octokit.js library included extra stuff I wouldn't need, which is an overkill for this use case.
To fetch a repository, you will use the https://api.github.com/repos/{owner}/{name} endpoint with some parameters. owner represents my GitHub username and name is the repository's name. A GET request should return a JSON data like so:
{
"id": 278287314,
"node_id": "MDEwOlJlcG9zaXRvcnkyNzgyODczMTQ=",
"name": "BolajiAyodeji",
"full_name": "BolajiAyodeji/BolajiAyodeji",
"private": false,
"owner": {
"login": "BolajiAyodeji",
"id": 30334776,
"node_id": "MDQ6VXNlcjMwMzM0Nzc2",
"avatar_url": "https://avatars.githubusercontent.com/u/30334776?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/BolajiAyodeji",
"html_url": "https://github.com/BolajiAyodeji",
...
},
"html_url": "https://github.com/BolajiAyodeji/BolajiAyodeji",
"description": "My automated GitHub Profile README built using TypeScript and GitHub Actions.",
...
"created_at": "2020-07-09T06:55:36Z",
"updated_at": "2023-11-11T09:25:16Z",
...
"stargazers_count": 4,
"watchers_count": 4,
"language": "TypeScript",
...
"open_issues_count": 0,
"license": {
"key": "mit",
"name": "MIT License",
...
},
...
"topics": [
"github-actions",
"github-api",
"hashnode",
"javascript",
...
],
"visibility": "public",
"forks": 19,
...
}
You can test this live yourself: api.github.com/repos/BolajiAyodeji/BolajiAyodeji.
If you make a request to GitHub's API using an access token through the Octokit.js library, you can make API requests without passing the
ownerparameter. GitHub will infer that from your token.
Now, we will create a fetchGitHubData() function in src/fetchGitHubData.ts that will accept an array of repository names as the parameter. This array will look like this:
[
"BolajiAyodeji",
"fed-unis-perf-eval",
"movie_reviews_sentiment_analysis",
"dotfiles"
];
Here's the function:
export async function fetchGitHubData(repos: Array<string>): Promise<string> {
const owner = "BolajiAyodeji";
const list = await Promise.all(
repos.map(async (repo) => {
const response = await fetch(`https://api.github.com/repos/${owner}/${repo}`);
if (!response.ok) {
throw new Error(`"${owner}/${repo}" not found. Kindy review your list of repositories.`);
}
const data = await response.json();
const {
html_url: url,
full_name: name,
stargazers_count: stars,
forks_count: forks,
description: desc
} = data;
return `<li><a href=${url} target="_blank" rel="noopener noreferrer">${name}</a> (<b>${stars}</b> ✨ and <b>${forks}</b> 🍴): ${desc}</li>`;
})
);
return `<ul>${list.join("")}\n<li>More coming soon :).</li>\n</ul>`;
}
In the function above, we loop through the array, fetch data for all the repositories, and extract the following fields:
html_url: link to the repository.full_name: name of the repository (including my username attached)stargazers_count: number of stars.forks_count: number of forks.description: description of the repository.
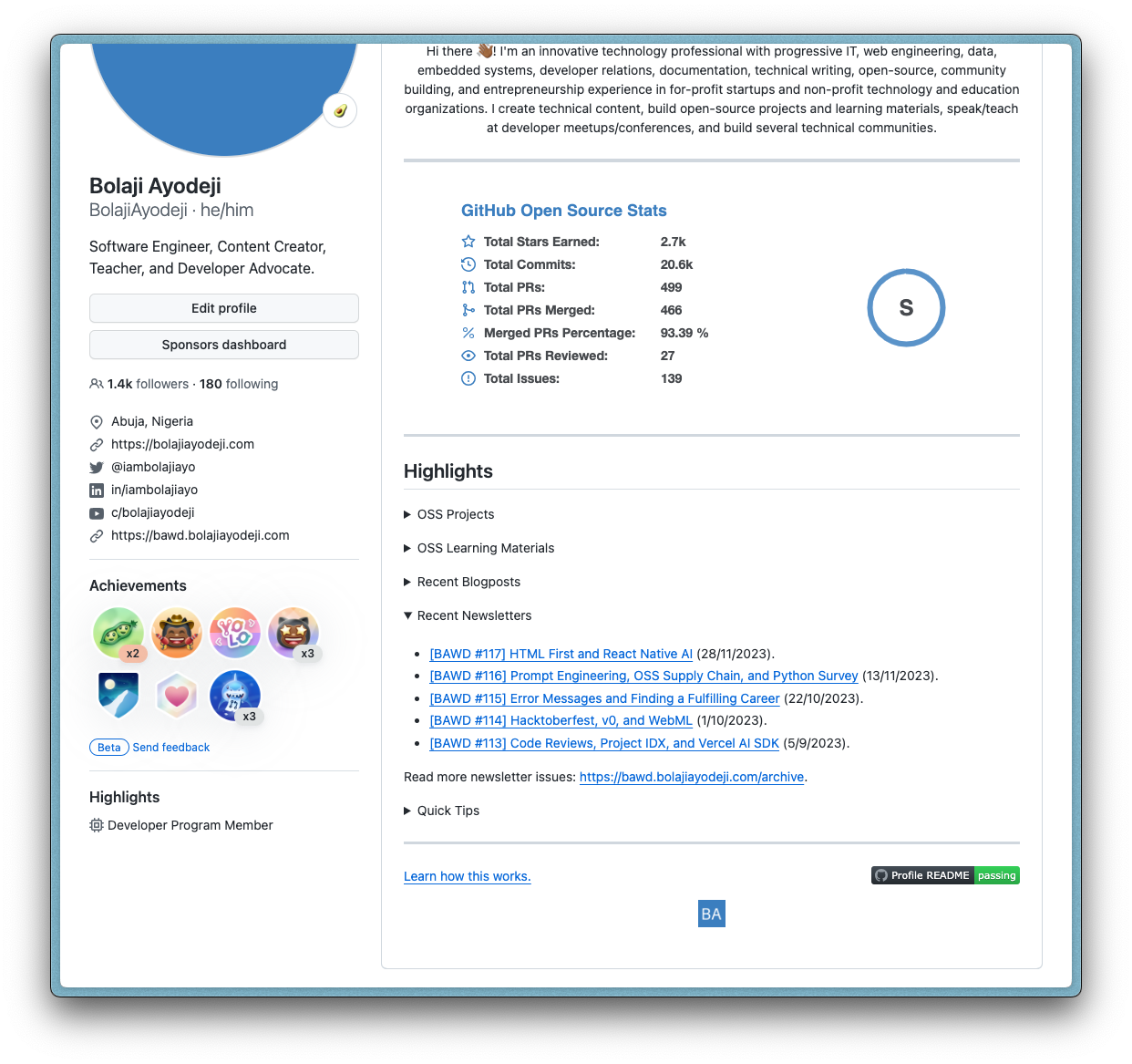
We then use the data to render an HTML list element (<li>) for each repository in the array, join all the lists together, add an additional static list element with custom text, and return an unordered HTML list element (<ul>). The final result should look like this:

This function is useless for now, but we will use it later in src/app.ts to render the markdown. Let's proceed!
Fetching the Data from RSS Feeds
We can use an RSS feed for the blog post and newsletter sections. According to Wikipedia, RSS (Really Simple Syndication) is a web feed written in XML (eXtensible Markup Language) that allows users and applications to access website updates in a computer-readable format. People use RSS to access the latest published content from a website page. Mostly, a user will use an RSS reader to access content from multiple XML files in an organized manner and read them.
My blog runs on Hashnode, which provides an rss.xml file by default on https://blog.bolajiayodeji.com/rss.xml. My newsletter also runs on Substack, which also provides an rss.xml file on https://bawd.bolajiayodeji.com/feed. So, each time a new post is added to my blog or newsletter, the RSS feed automatically includes the page's current data. This makes it a good data source for my GitHub Profile.
Since both RSS feeds are similar in structure, I can create a fetchRssData() function in src/fetchRssData.ts for both. We will first use the rss-parser library to turn the RSS XML feeds into JavaScript objects and then iterate to find the necessary fields.
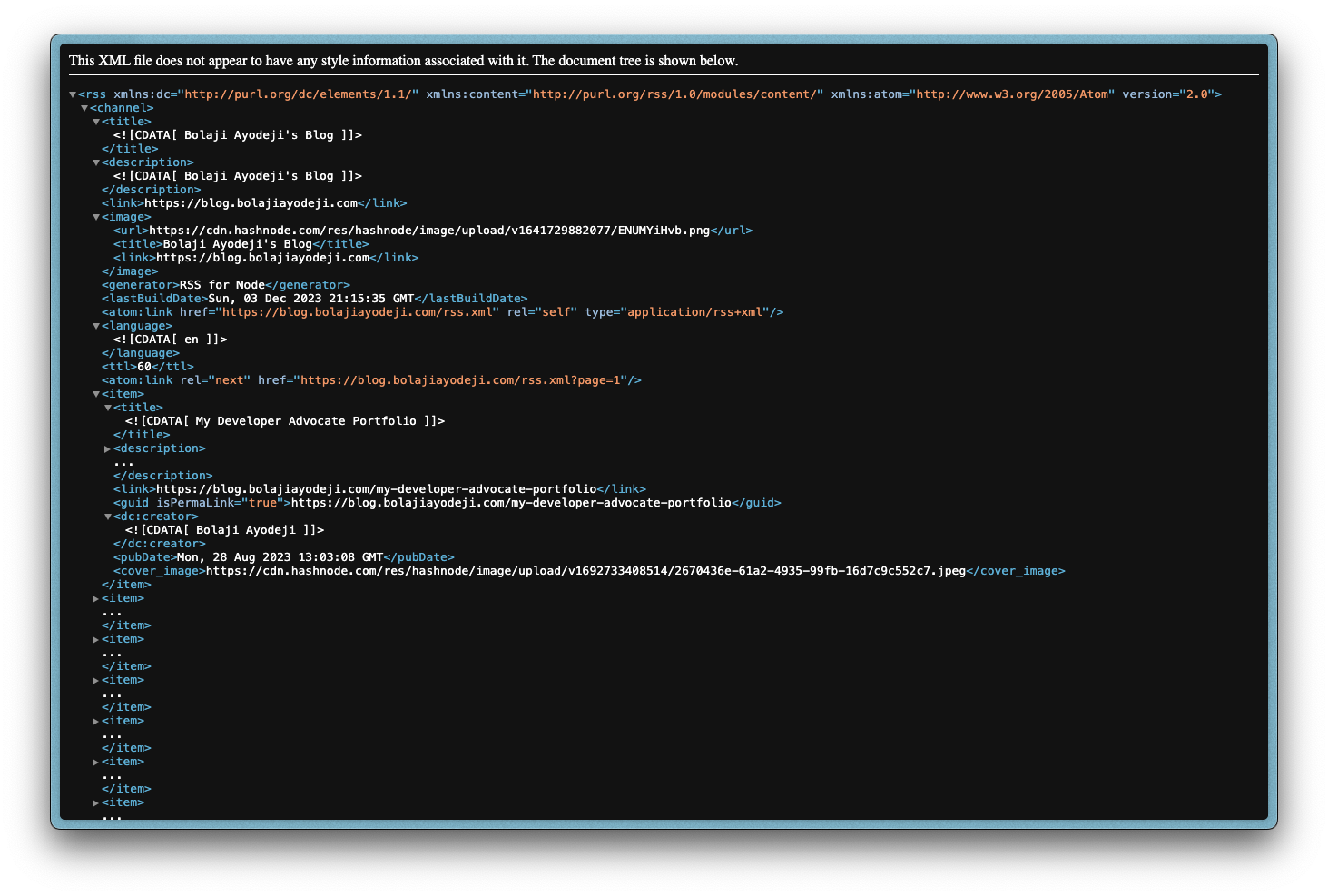
The XML looks like this (view the image below live for a better experience):
The parsed version looks like this:
{
"items": [
{
"creator": "Bolaji Ayodeji",
"title": "My Developer Advocate Portfolio",
"link": "https://blog.bolajiayodeji.com/my-developer-advocate-portfolio",
"pubDate": "Mon, 28 Aug 2023 13:03:08 GMT",
"dc:creator": "Bolaji Ayodeji",
"content": "...",
"contentSnippet": "...",
"guid": "https://blog.bolajiayodeji.com/my-developer-advocate-portfolio",
"isoDate": "2023-08-28T13:03:08.000Z"
},
{ another item... }
{ more items... }
{
"creator": "Bolaji Ayodeji",
"title": "How to Deploy a Machine Learning Model to the Web",
"link": "https://blog.bolajiayodeji.com/how-to-deploy-a-machine-learning-model-to-the-web",
"pubDate": "Sat, 03 Sep 2022 08:49:08 GMT",
"dc:creator": "Bolaji Ayodeji",
...
}
...
}
This is what the final function will look like:
import Parser from "rss-parser";
const parser = new Parser();
export async function fetchRssData(url: string): Promise<string> {
const feed = await parser.parseURL(url);
const list = feed.items.slice(0, 5).map((item) => {
const date = new Date(item.pubDate as string);
const publishedDate = `${date.getDate()}/${date.getMonth() + 1}/${date.getFullYear()}`;
return `<li><a href=${item.link} target="_blank" rel="noopener noreferrer">${item.title}</a> (${publishedDate}).</li>`;
});
return `
<ul>
${list.join("")}
</ul>\n
${
url.endsWith("rss.xml")
? `Read more blog posts: ${url.replace(/\/rss.xml$/, "")}`
: `Read more newsletter issues: ${url.replace(/\/feed$/, "")}`
}.
`;
}
In the function above, we use the RSS link to fetch the data, extract just the first five items (posts), and extract the following fields:
pubDate: timestamp for when the content was published.link: link to the post.title: title of the post.
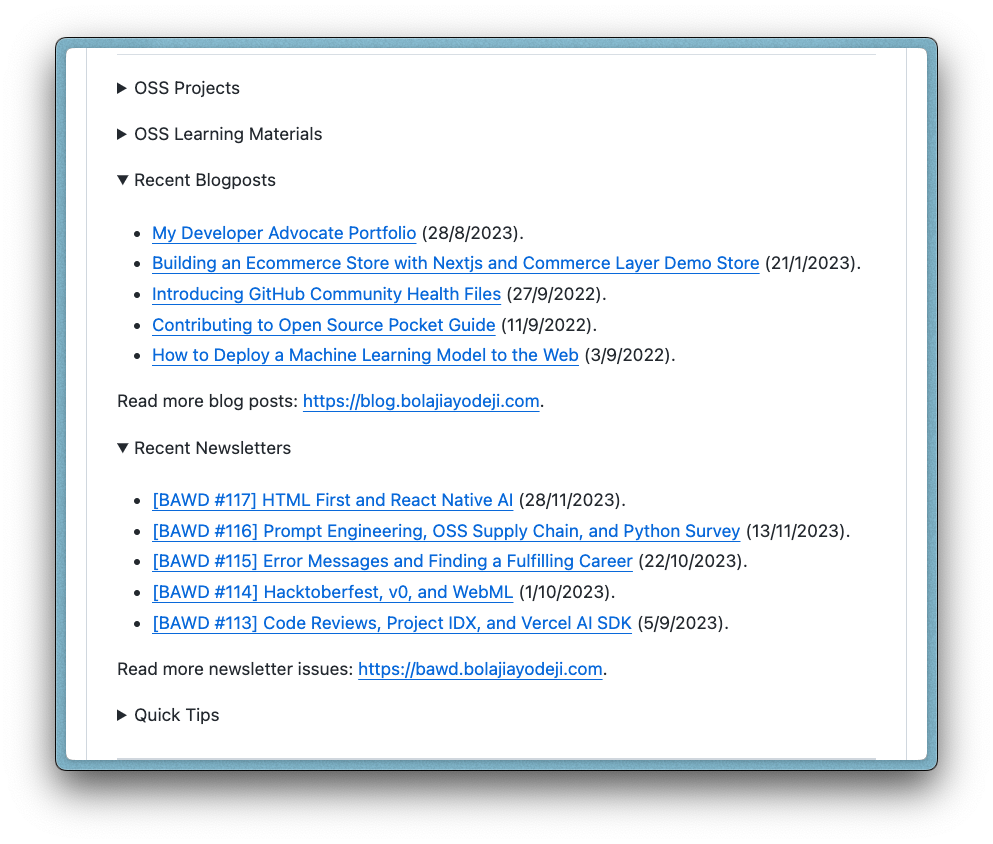
We then use the data to render an HTML list element (<li>) for each published post, do some date formatting, join all the lists together, add an additional static list element with custom text, and return an unordered HTML list element (<ul>). The final result should look like this:
Generating the Final Markdown File
Now that we have the fetchGitHubData() and fetchRssData() functions, let's combine everything and generate the README.md file we need. In src/app.ts add the following code:
import * as fs from "fs";
const md = require("markdown-it")({
html: true, // Enable HTML tags in source
breaks: true, // Convert '\n' in paragraphs into <br>
linkify: true // Autoconvert URL-like text to links
});
import { fetchRssData } from "./fetchRssData";
import { fetchGitHubData } from "./fetchGitHubData";
const blogFeedUrl = "https://blog.bolajiayodeji.com/rss.xml";
const newsletterFeedUrl = "https://bawd.bolajiayodeji.com/feed";
const ossProjectRepos = [
"BolajiAyodeji",
"fed-unis-perf-eval",
"movie_reviews_sentiment_analysis",
"dotfiles"
];
const ossLearningMaterialRepos = ["deploy-ml-web-workshop", "cl-composable-commerce-workshop"];
const githubUsername = "BolajiAyodeji";
const websiteUrl = "https://bolajiayodeji.com";
const blogUrl = "https://blog.bolajiayodeji.com";
const newsletterUrl = "https://bawd.bolajiayodeji.com";
const youtubeUrl = "https://youtube.com/c/bolajiayodeji";
const slidesUrl = "https://slides.com/bolajiayodeji";
const twitterUrl = "https://twitter.com/iambolajiayo";
const linkedinUrl = "https://linkedin.com/in/iambolajiayo";
const githubSponsorsUrl = "https://github.com/sponsors/BolajiAyodeji";
const patreonUrl = "https://patreon.com/bolajiayodeji";
async function generateMarkdown() {
const websiteBadge = `[](${websiteUrl})`;
const hashnodeBadge = `[](${blogUrl})`;
const substackBadge = `[](${newsletterUrl})`;
const youtubeBadge = `[](${youtubeUrl})`;
const slidesBadge = `[](${slidesUrl})`;
const linkedinBadge = `[](${linkedinUrl})`;
const twitterBadge = `[](${twitterUrl})`;
const githubSponsorsBadge = `[](${githubSponsorsUrl})`;
const patreonBadge = `[](${patreonUrl})`;
const profileCountBadge = ``;
const githubStatsCardDark = `[](https://github.com/${githubUsername}/${githubUsername}#gh-dark-mode-only)`;
const githubStatsCardLight = `[](https://github.com/${githubUsername}/${githubUsername}#gh-light-mode-only)`;
const markdownText = `<div align="center">\n
${websiteBadge} ${hashnodeBadge} ${substackBadge} ${youtubeBadge} ${slidesBadge} ${linkedinBadge} ${twitterBadge} ${githubSponsorsBadge} ${patreonBadge} ${profileCountBadge}\n
---\n
Hi there 👋🏾! I'm an innovative technology professional with progressive IT, web engineering, data, embedded systems, developer relations, documentation, technical writing, open-source, community building, and entrepreneurship experience in for-profit startups and non-profit technology and education organizations. I create technical content, build open-source projects and learning materials, speak/teach at developer meetups/conferences, and build several technical communities.\n
---\n
${githubStatsCardDark}\n
${githubStatsCardLight}\n
</div>\n
---\n
## Highlights
<details>\n
<summary>OSS Projects</summary>\n
<br />
Here are some of my other projects you might want to check out that are not pinned:\n
<br />\n<br />
${await fetchGitHubData(ossProjectRepos)}\n
</details>\n
<details>\n
<summary>OSS Learning Materials</summary>\n
<br />
Here are some of my unique-styled workshop materials you can use to learn key concepts at your own pace:\n
<br />\n<br />
${await fetchGitHubData(ossLearningMaterialRepos)}\n
</details>\n
<details>\n
<summary>Recent Blogposts</summary>\n
<br />
${await fetchRssData(blogFeedUrl)}\n
</details>\n
<details>\n
<summary>Recent Newsletters</summary>\n
<br />
${await fetchRssData(newsletterFeedUrl)}\n
</details>\n
<details>\n
<summary>Quick Tips</summary>\n\n
- 💬 How to reach me: DM [@iambolajiayo](https://twitter.com/iambolajiayo) on X (Twitter).\n
- 📬 Where to find me: Subscribe to my [newsletter](https://bawd.bolajiayodeji.com/subscribe) to hear from me bi-weekly or send a game request on [chess.com](https://chess.com/member/bolajiayodeji).\n
- 📖 Book recommendations: [Knowing God by J. I. Packer](https://bit.ly/3EdCFUW) and [Atomic Habits by James Clear](https://bit.ly/45r1kBH).\n
- 💙 Fun fact: I'm in a blissful relationship [with Jesus Christ](https://biblegateway.com/passage/?search=1+Corinthians+15%3A1-11&version=NKJV). Check [this](https://bit.ly/3KYYHij) out :).\n
</details>\n
---\n
<a href="#">Learn how this works.</a> <a href="https://github.com/BolajiAyodeji/BolajiAyodeji/actions/workflows/build.yml"><img src="https://github.com/BolajiAyodeji/BolajiAyodeji/actions/workflows/build.yml/badge.svg" align="right" alt="Rebuild README.md file"></a>\n
<div align="center">\n
<a href="https://bolajiayodeji.com" target="_blank" rel="noopener noreferrer"><img src="https://bolajiayodeji.com/favicon.png" width="30" /></a>\n
</div>`;
const result = md.render(markdownText);
fs.writeFile("README.md", result, (error) => {
if (error) throw new Error(`Something went wrong: ${error}.`);
console.log(`✅ README.md file was succesfully generated.`);
});
}
generateMarkdown();
Here, I manually add all the static markdown content that existed before (text, badges, etc.) in the markdownText variable, add the new dynamic sections with the functions, render the markdown file in the result variable, and create the markdown file using Node.js's fs.writeFile() method.
Setting up the CI/CD Pipeline with GitHub Actions
Now, to the cool part! So far, the major work has been done, and if I run npm run build and npm run start locally, a new README.md file will be generated, including any changes that come from the API and RSS feeds. But I shouldn't have to do this manually every time I want to change something, right? So what can we do?

That's where CI/CD and cron jobs come in.
CI/CD Pipeline
If you're new to this, CI/CD (which means Continuous Integration / Continuous Delivery or Deployment) is a process used in software engineering to merge code and automate specific repeated sequence of tasks (e.g., tests) that are required before and/or after deploying a software (e.g., releases) for users to access. In our case, we want to run the npm run start command on the cloud repeatedly on a fixed day/time and push the updated README file to the special GitHub repository using Git. This way, anytime a user views the GitHub profile, they see the latest content (the latest deployed version of the README based on the schedule). If there's an error, the process is expected to fail and return the errors in the log file.
This is a basic use case of CI/CD. For more extensive software, you would have a more complex pipeline (managed mainly by DevOps or SRE engineers) handling things like running unit/integration tests, updating data, release notes, etc.
Cron Jobs Scheduling
The scheduling would be handled with something called a Cron Job. This is the standard method of scheduling specific tasks on a server at fixed times. At the right time or interval, certain tasks (jobs) will be executed. If you're new to this concept, you might be able to visualize how this will work based on our Profile README use case. It doesn't make sense to update the README file every second since I'm not publishing new content every second. To avoid wasting resources, setting up a Cron Job to execute the logic daily or even weekly is ideal. With this, a user will still get the most recent content. You can adjust the schedule to fit your needs if you're doing this for another use case.
Cron jobs are composed of expressions. An expression includes a string of five fields (* * * * *) which will contain numbers and some special characters. The character asterisk (*) represents any value, comma (,) represents a list of values, hyphen (-) represents a range of values, and slash (\) represents a step of values. Each field represents the following:
Minute (0 - 59).
Hour (0 - 23).
Day of the month (1 - 31).
Month (1 - 12).
Day of the week (0 - 6 with 0 being Sunday).
A cron expression * * * * * will mean run every minute, */30 * * * * will mean run every 30 minutes, */30 7 * * * will mean run every 30 minutes between 07:00 and 07:59, */30 7-10 * * * will mean run every 30 minutes between 07:00 and 10:59, * 12-18 * * * will mean run every minute between 12:00 and 18:00, 0 12-18 * * * will mean run hourly between 12:00 and 18:00, 0 12-18 5 5 * will mean run hourly between 12:00 and 18:00 on the 5th day of March only, 0 12 * * * will mean run daily at 12:00, etc. There are so many permutations, and if you're interested, you can create, test, and practice different cron expressions using services like Cron Expression To Go or Crontab Guru.
GitHub Actions
You can set up a CI/CD pipeline using several tools like CircleCI, Travis CI, GitHub Actions, etc. We will use GitHub Actions for this use case since it's provided by the platform we're already using (but you can achieve the same with the others). GitHub Actions allows you to automate your build, test, and deployment pipeline with workflows inside a GitHub repository. These workflows can run on every pull request to your repository, merged pull requests, cron jobs, etc. You can learn more about GitHub Actions by reading this guide on GitHub Docs.
In the .github/workflows/build.yml, add the following code:
name: Profile README
on:
push:
workflow_dispatch:
schedule:
- cron: "0 6 * * *"
jobs:
build:
runs-on: ubuntu-latest
steps:
- name: Checkout Repo
uses: actions/checkout@v4
- name: Use Node.js
uses: actions/setup-node@v4
with:
node-version: "18"
- name: Install Dependencies
run: npm install
- name: Rebuild README.md File
run: npm run start
- name: Commit and Push if Changed
run: |-
git add .
git diff
git config --global user.email "mailtobolaji+actionsbot@gmail.com"
git config --global user.name "BA Actions Bot"
git commit -m "docs: auto-update README.md" -a || exit 0
git push
Here, I configure GitHub Actions to set the name of the build, set the determinant of the pipeline (a cron schedule), set the cron schedule to run 06:00 AM daily (GitHub’s cron schedule runs with the UTC timezone), add some steps, install all the required dependencies, run the npm start command, generate the new README.md file, and push the changes using Git (if there are any changes in the file). If no changes exist, the process terminates, and no commit is pushed.
If you push the entire code to GitHub, the build will run automatically in GitHub Actions upon each push. But also, it will run on its own every day as scheduled. You can see the log of all builds in the "Actions" tab of the repository.
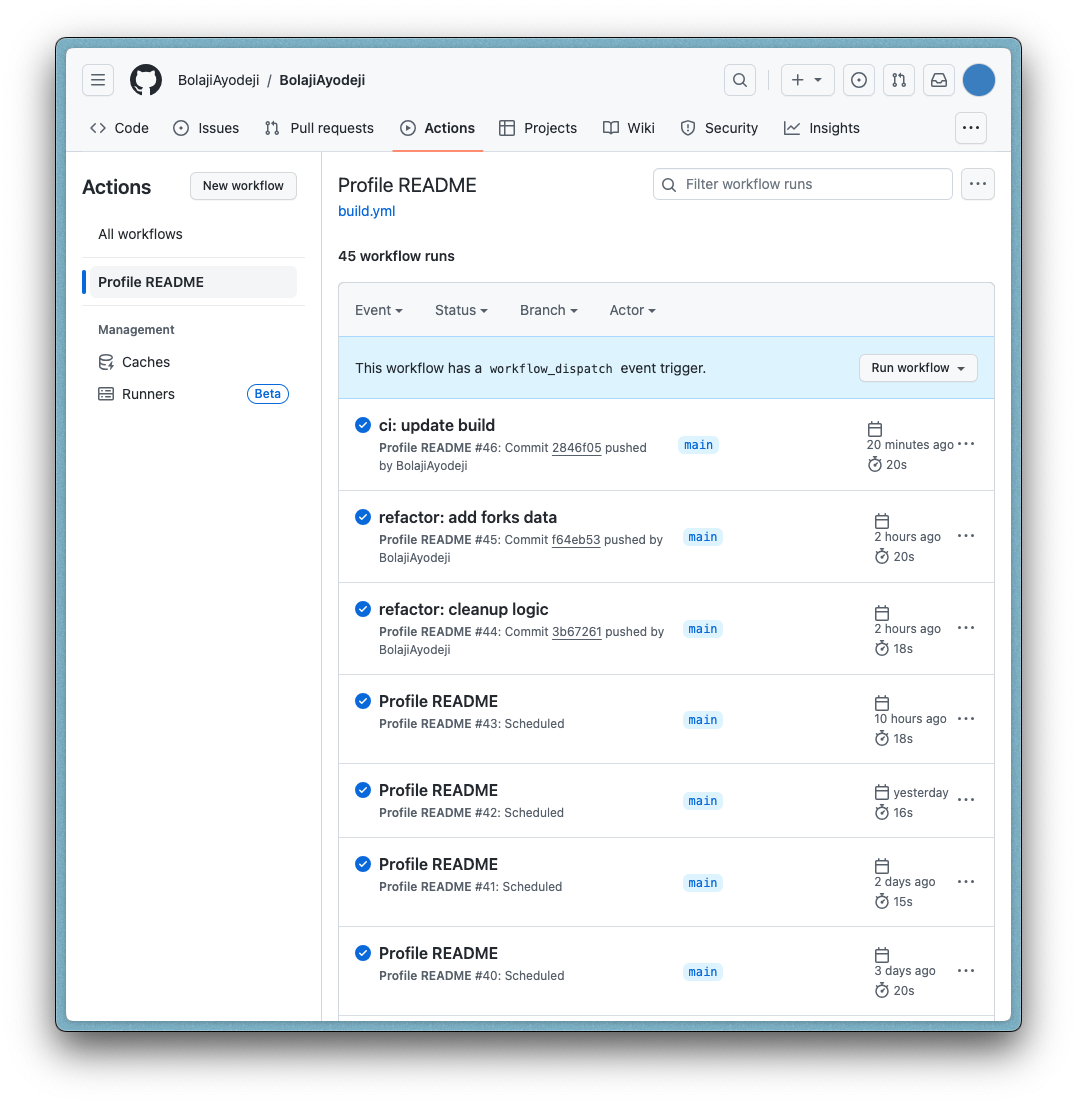
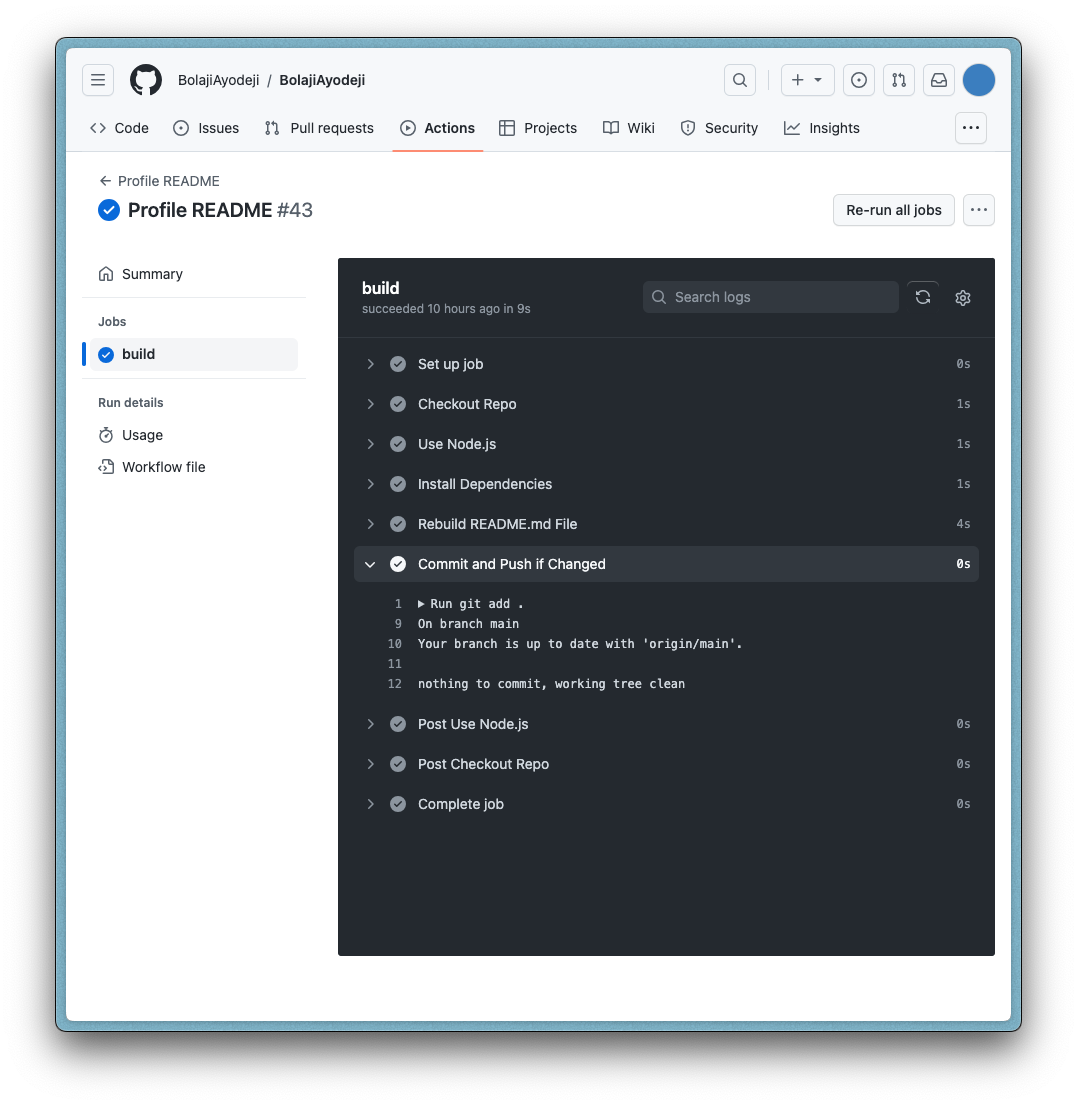
Also, kindly note that you might experience some delays with GitHub Actions for the first time. Initially, I chose 00:00 as my cron schedule, but it wasn't working. Research showed that sometimes it fails during peak hours, like the first hour of the day when usage is high. I switched to 06:00, which still failed, but started working fine the next day or so. In summary, GitHub Actions can be unpredictable for cron jobs, and you can use a dedicated infrastructure if you need a reliable execution at an exact time. But for this use case, it works just fine once it gets stable (nothing critical is going on here).
Custom GitHub Bot Account
If you observed, I used a custom user.email and user.name when setting up the GitHub actions push step. If you use a random email, it will push to GitHub with a non-existent account (no profile picture will be shown). My first thought was to use my actual GitHub account email that will push the changes as myself. But to make things much more neat, I created a new GitHub account that acts as a bot. This way, I can tell all the commits that were auto-generated from the script from mine.
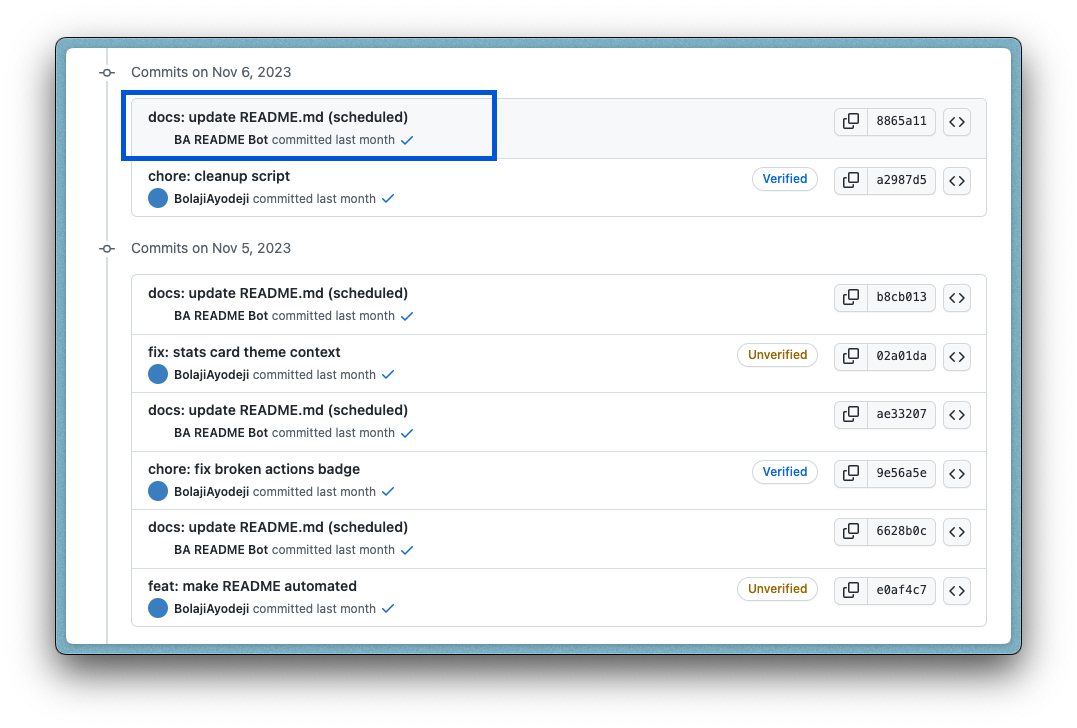
To create the account, you can use your existing Gmail (if you don't have Gmail, use any email). Google allows you to create email aliases and receive emails from all in your inbox. All you must do is add a plus (+) sign after your email address and some custom text. Generally, I use this hack to create multiple email aliases for my Gmail so I can easily track specific emails based on context (e.g. if the email is bolaji@gmail.com, an alias can be bolaji+actionsbot@gmail.com). You're good to go once you create the account and set a nice name/profile picture. If you use this email to configure Git in the GitHub Actions, it will reflect accordingly.
PS: if you choose to do this with a Gmail alias, ensure to save the password somewhere because if you forget the password and need to log in (maybe to change the profile picture), you won't be able to use the "Forget password" feature with a Gmail alias email address. GitHub's form validation filters it out.
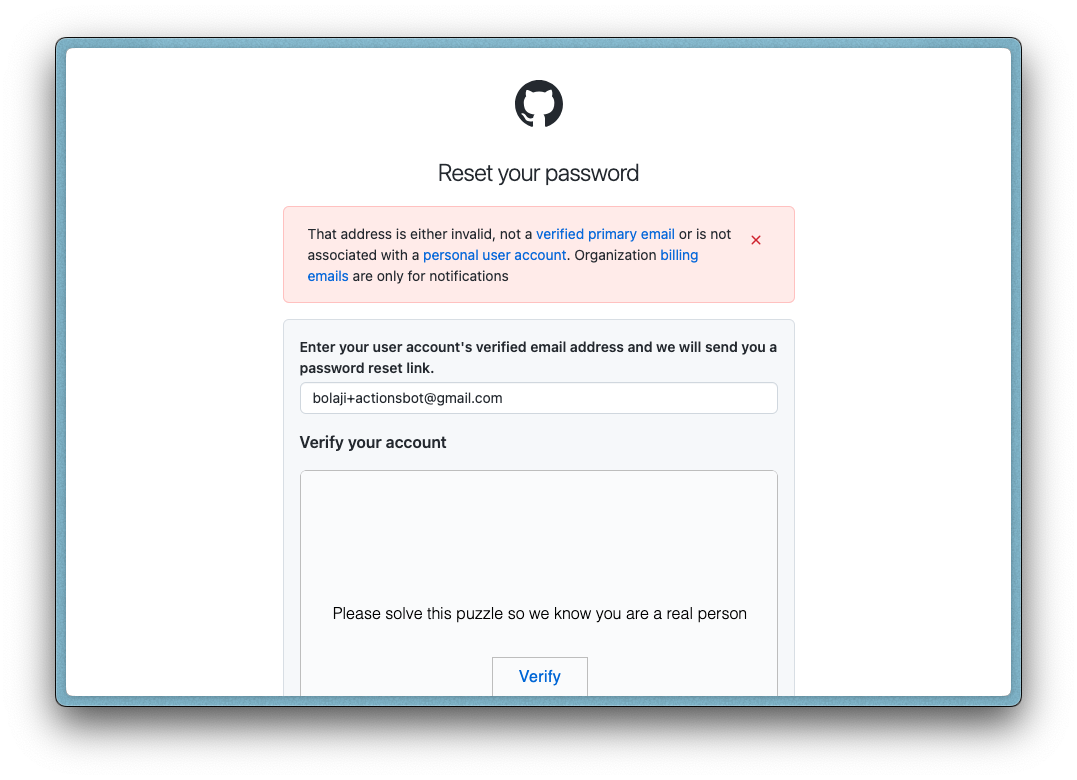
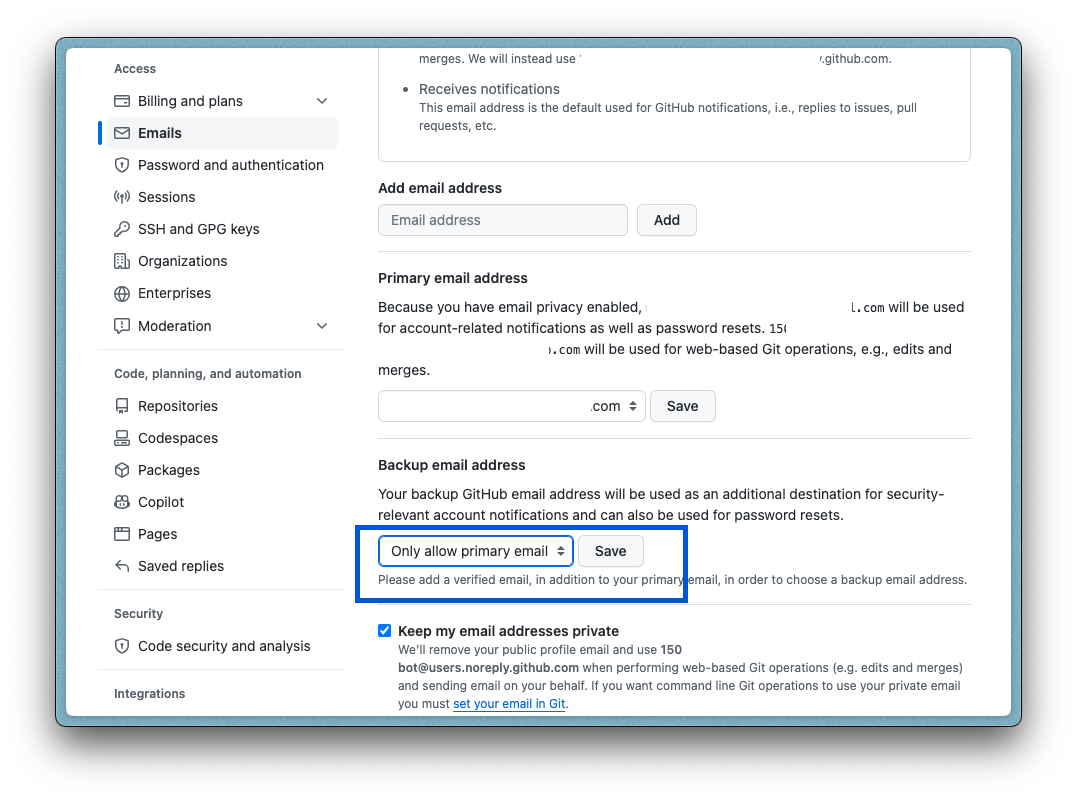
However, to solve this, manually change the "Backup email address" option to "Only allow primary email" in GitHub's dashboard (Settings > Emails).
Conclusion
That's about it! Now, you've learned how to automate scripts with CI/CD. If you're new to many of the concepts discussed in this tutorial, you should have learned some new things you can expand on. You can also extend the ideas here and customize the script to do anything you want it to. Just find a data source and do your thing.
I'm keen to see what you build with this, so please leave a comment with a link to your GitHub README Profile if you do something like this. Remember that this goes beyond markdown files; you can use the automated script idea to do anything else!
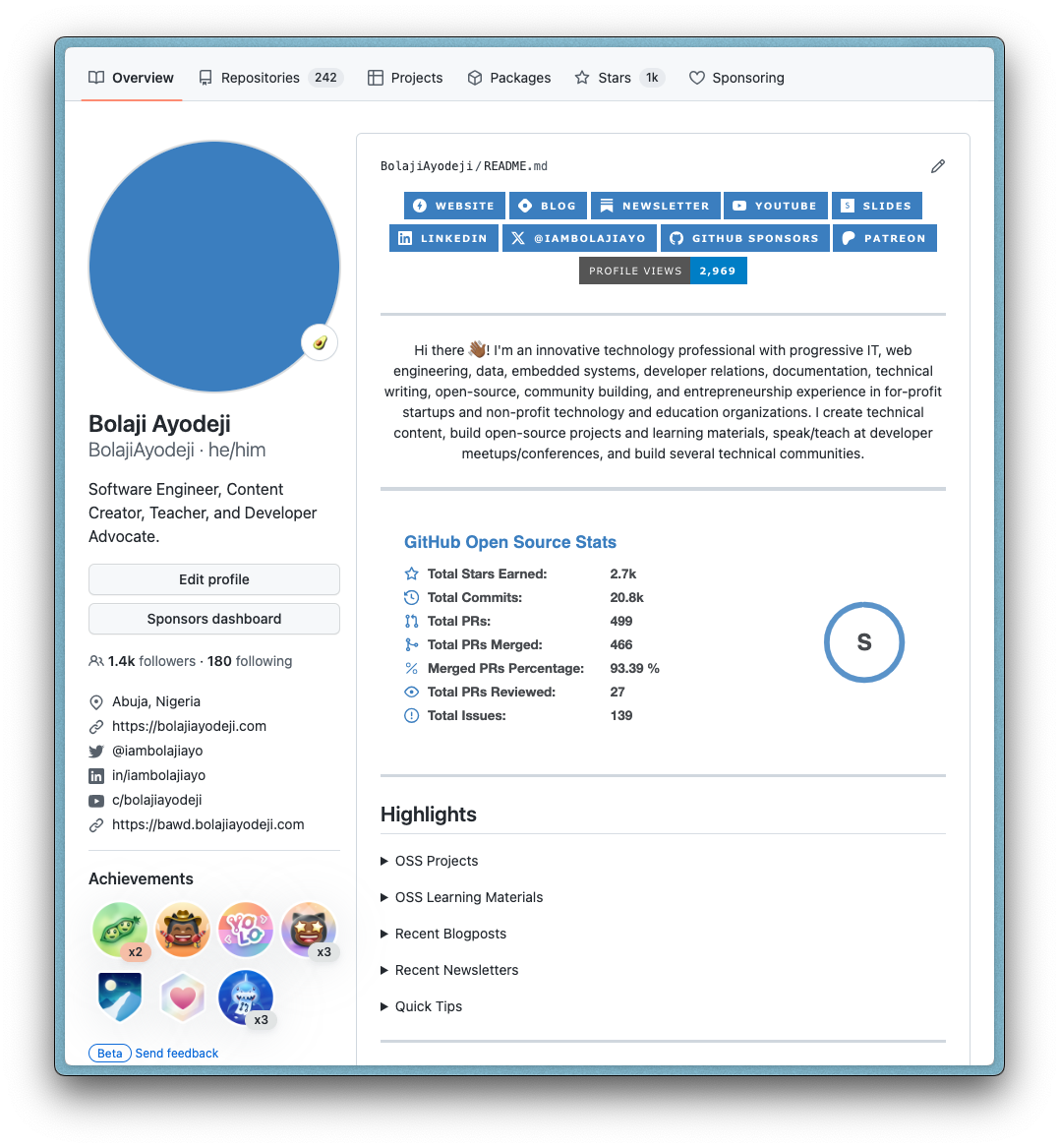
I'm happy with the results and I look forward to making more changes in the future as the need arises :). Thanks for reading this far; cheers!